This blog was originaly posted here
Introduction
This year in Google Summer of Code 2022, the goal of the enviroCar App: Voice Command project was to provide a better user-friendly experience by automating the actions of the enviroCar Android application using voice commands. I have worked on various goals of the project which you can read about in my previous blogs. In my final blog post, I want to present the outcomes of the project, which have been achieved over the last 12 weeks.
Project Goals
Prepare the enviroCar App for voice command integration
The first goal for the project was to prepare the enviroCar App for voice command integration. By developing software
designs, such as a speech recognition pipeline, component diagram, and UML (Unified Modeling Language) class diagram, I
was able to accomplish this goal. Have a look at the previous blogs to
check out those diagrams. Based on this architectural design groundwork, I implemented the voice command functionality
within a separate Gradle module as
part of the enviroCar App.
Notable commits:
- Added voice command module (see PR)
Trigger voice command and translate speech to plain text
Interacting with the enviroCar Android app while driving is a serious concern. There are multiple benefits to voice triggers versus button taps that trigger voice recognition. The most important concern is that touching a device while driving is a risky distraction since it could cause an accident. Hence, a voice trigger feature was required. To achieve this, we used the AimyBox library with a prebuilt CMU Pocketsphinx language model for the voice trigger. I chose the word “enviroCar Listen” as the voice trigger, because that was direct and on point. I tested it for the voice trigger with the Pocketsphinx library and it was giving the highest accuracy. The mid-term blog gives implementation details for this goal.
Furthermore, I
utilized GooglePlatformSpeechToText
, which recognizes the user’s speech and translates it to plain text and vice versa. The voice command feature was
intended to be made available to users via the app’s settings. I implemented the whole voice command activation flow,
which includes enabling the feature in settings as well as giving visual feedback to the user and asking for microphone
permissions.
Below is a screen recording that shows how to enable the voice commands feature and voice trigger in the enviroCar
application:
Notable commits:
- Integrated Aimybox library in the voice-command module
- Integrated Pocketsphinx library + voice trigger
- Added Pocketsphinx model
- Added voice command option in settings
- Ask for microphone permission after enabling voice command
- Added a check for microphone permission in the main activity.
- Custom good-looking snack bar for voice trigger
Recognize the user’s intent via NLP/NLU
The third goal was to use natural language processing/natural language understanding (NLP/NLU) to recognize the user’s intent and carry out the appropriate action in the enviroCar App. To achieve this, we used Rasa Open Source to recognize the intent and run custom actions to perform voice commands in enviroCar. Further implementation details of this goal are covered as part of the mid-term blog.
Notable commits:
- Added pipeline configurations to the model
- Added training data for starting/stopping track recording
- Added stories for start, stop, and unspecified action for track recording
Develop a request and response schema for voice commands
As discussed in the mid-term blog
, recognizing the user’s intent via NLP/NLU is not enough to integrate voice commands in the application. The NLP/NLU
part will only identify a specific entity and provide responses with data to some extent. It is necessary to check a
number of prerequisites before beginning track recording. Rasa should consider these requirements and respond to the
user as necessary, such as “Please select a car before recording the track”. To handle this, I created a suitable
request and response model schema along with the required stories and rules. In
the earlier blog, I mentioned the
stories and showed snippets for the stories of start/stop voice commands. I also worked on adding rules for the same.
Rules are a type of training data used to train your assistant’s dialogue management model. They describe short pieces
of conversations that should always follow the same path. These are the rules for starting and stopping recording:
- rule: Start recording
steps:
- intent: main_ui_recording
entities:
- recording_start_action
- action: action_start_recording
- rule: Stop recording
steps:
- intent: main_ui_recording
entities:
- recording_stop_action
- action: action_stop_recording
The snippet shows rules for voice commands that trigger starting and stopping track recording. For instance, the rule “ Start recording” describes that when an intent “main_ui_recording” is triggered by a dedicated sentence it has to run the action “action_start_recording”, which runs the custom code that is needed to start recording.
After testing the intents, entity extraction, and stories, we had to develop a custom Rasa server request payload schema with additional data sent from the enviroCar application. Such a schema was required to achieve effective interaction between the enviroCar application and the Rasa server as well as for clean and production-level code. A proper model schema helped us to document the Rasa server request/response payloads. However, the default channel provided by Rasa does not support additional data fields. Channels are different connectors to which you can connect your Rasa server.
For example, if you want to use the Rasa server for your website, which requires a username and a password to connect with the website then you can create a custom channel that requires a username and password in the request model.
You can read more about this here.
With this in mind, I created a dedicated enviroCar channel. It accepts extra data referred to as “metadata” in the request model. Using this metadata, the enviroCar application can send a bunch of data, like recording status, whether GPS is on, or the number of cars available.
Request payload for starting the recording:
{
"sender": "cdhiraj40",
"message": "start recording",
"metadata": {
"recordingMetadata": {
"recording_status": "RECORDING_STOPPED",
"recording_mode": "OBD_MODE",
"isDashboardFragment": true,
"has_location_permission": true,
"has_bluetooth_permission": true,
"gps": true,
"car": true,
"bluetooth": true,
"obd_adapter": true
,
"type": "RECORDING"
}
}
As mentioned above, the enviroCar application can send metadata that enables the Rasa server to know which prerequisites are fulfilled for a particular request.
Similarly, I created a response model, which is further divided into “ActionModel”, “CustomEventModel” and “ ActivityExtrasModel”. The action model contains information on what next action has to be taken e.g., stand by, recognition, or nothing . The custom event model takes care of various custom events that are sent between activities, like navigating to the car selection screen or starting the recording.
[{
"recipient_id": "cdhiraj 40",
"custom": {
"query": "start recording",
"reply": "Sure, I will start recording",
"action": {
"custom_event": {
"type": "Recording",
"name": "START"
},
"next_action": "STANDBY",
"Activity_class_name": "org.envirocar.app.views.recordingscreen.RecordingScreenActivity.java",
"activity_extras": null
},
"data": {
"intent": "main_ui_recording"
}
}
}]
As mentioned above, the enviroCar application receives a response in accordance with this schema. It holds information about the next action, custom events, extra data if there is any, and a reply which is spoken in the app.
Rasa offers Custom Actions that allow us to run custom code with stories. For the enviroCar voice command feature, it was necessary to implement Custom Actions for the requirements listed below:
- Checking the status of prerequisites for starting recording (Recording status, GPS, Bluetooth, OBD2-Adapter, selected car, etc.)
- Checking the status of prerequisites for selecting a car (Cars available, active screen status, etc.)
Notable Commits:
- Added rules for start-stop recording
- Developed request schema modal
- Developing response schema model
- Start recording action
- Added rules and stories for stop recording
- Implemented stop recording command
Adding voice commands to automate enviroCar App actions
After finishing the groundwork, it was time to add voice commands that enable enviroCar App actions. I started with the most important voice command for the project – the start/stop recording functionality – as it’s potentially dangerous to use your phone while driving.
Start/Stop Recording
As discussed above, I implemented the custom actions for start/stop recording and a follow-up action to handle all prerequisites. Here’s a flow chart explaining the whole workflow of the start-stop voice commands:
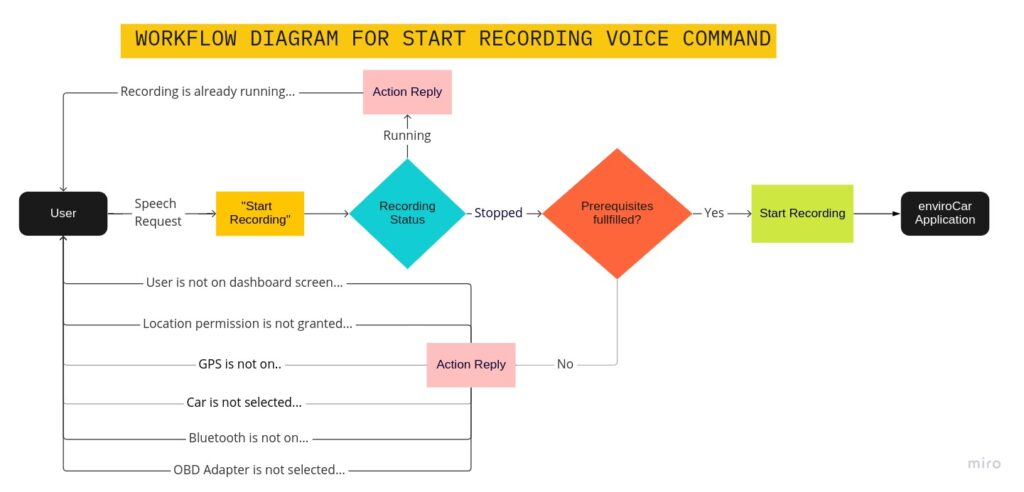
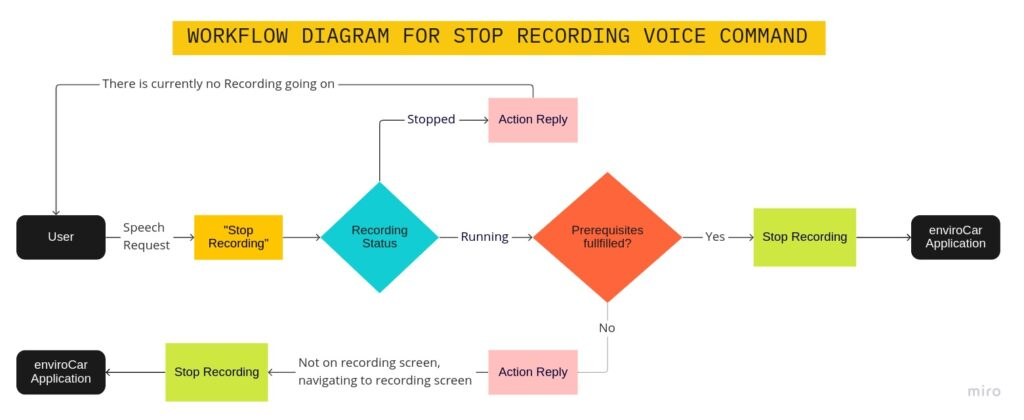
The diagrams above show the voice command workflow for starting and stopping track recording:
- The custom action is triggered by the user speaking “start recording”, which further checks every prerequisite needed for starting recording.
- Once prerequisites are fulfilled, the application will start recording and navigate to the track recording screen.
- Similarly, to stop recording, every prerequisite is checked for eg. “recording should be on” and if fulfilled the application will stop recording.
Here is a screen recording showing the whole workflow of the start-stop voice commands:
- Start recording
- Stop recording
Select a car
Similarly, I implemented the custom actions for selecting a car, verifying the selection, and a follow-up action to handle all prerequisites. Here’s a flow chart explaining the whole workflow of the car selection voice commands:
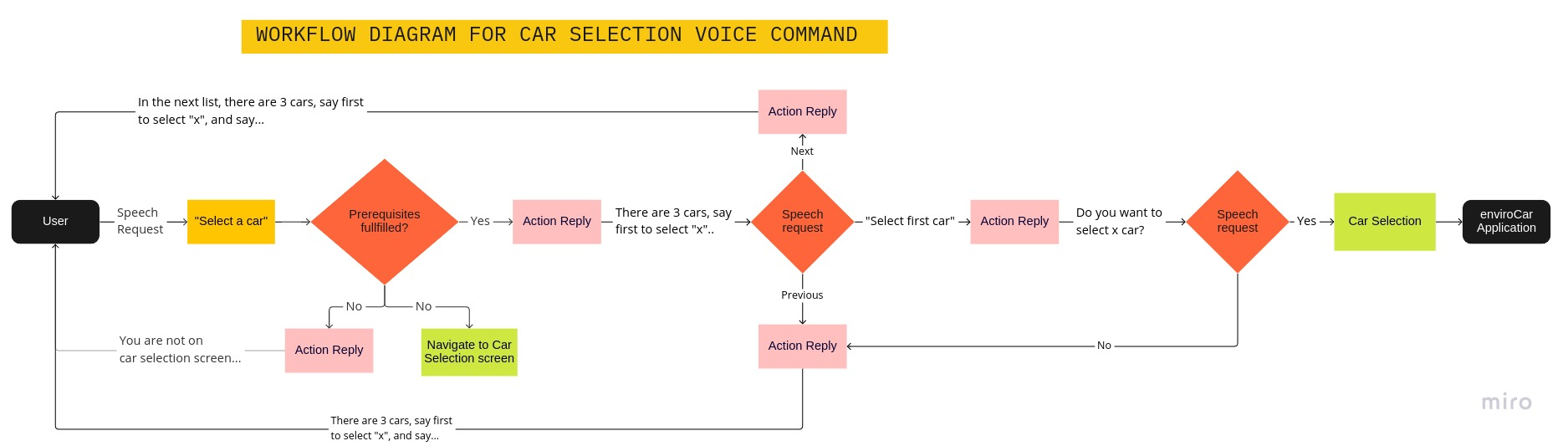
The following are the main steps in the car selection workflow:
- The custom action is triggered by the user speaking “select a car”, which further checks every prerequisite needed for selecting a car, eg., are cars available or is the user on the car selection screen, etc.
- Once prerequisites are fulfilled, the application says the first one/two/three cars depending on the availability of the cars.
- A user either can select a particular car by saying “Select first/second/third car”, say “next” to select from the next list (if existent), or say “previous” to select from the previous list (if a user is not on the first list of cars).
- Upon selection of a car, the command is further verified by asking “Do you want to select x car?” The user can reply “yes” or “no”. Speaking “yes” will select the car, otherwise, the whole process repeats from where it was left.
Here is a screen recording showing the whole workflow of the car selection:
Notable Commits:
- Implemented start recording in the enviroCar application
- Implemented stop recording in the enviroCar application
- Implemented car selection in the enviroCar application
If you would like to know more about my GSoC’22 work, please refer to my introduction blog , mid-term blog, and commits.
Future Work
As part of GSoC’22, we focussed mainly on automating the track recording screen and car selection screen via voice commands. There is still some space for more voice command improvements which will be tackled in the future.
I will continue to work on the project, resolve the bugs and improve the existing features. Below are some of the future improvements:
- Add new car voice command
- Writing more tests
- Integrate CI/CD into the enviroCar Rasa bot project
- Adding code analyzer to envirocar Rasa bot project
Summary
For me, the GSoC’22 journey was an excellent learning experience. It was a terrific learning experience to create something from scratch, design UML diagrams before implementing them, and see how the feature can be addressed using several techniques. Working actively on the enviroCar Android app and on the Rasa side, I was able to learn various aspects of the development of a feature such as:
- Working with a large codebase
- Writing clean, readable, and production-level code
- Working in a team to understand how a feature can be addressed using various software engineering techniques
- Practicing agile development methods ** In conclusion, I was working on two repositories: enviroCar App and enviroCar-Rasa-bot. I added the voice command feature for start/stop recording, and car selection. There were more than 120 commits for both projects. I believe the work I have done will be a good starting point for future improvements for the voice commands as far as implementing and taking into account how crucial the feature is in the app.
Overall, my experience participating in Google Summer of Code with 52°North has been enriching and has significantly advanced my developer skills. I look forward to continuing to contribute to the feature and working to become a better developer.
I want to thank Sebastian,, my mentor, for being open to my ideas, looking over my code, reviewing my approaches, and helping me with implementations. Working with him was a remarkable learning experience and I was glad to be a mentee under him.
In the end, I would like to express my gratitude to 52°North for providing me with this wonderful chance to spend my summer working on the enviroCar project as part of GSoC 2022.